从50年代的 Lisp 开始,函数式编程已经存在很长时间了。(在过去的几年里的Clojure、Scala、Erlang 和Elixir)。那么,函数式编程也就是FP(Functional Programming)到底是什么?和命令式编程(Imperative programming)有什么区别?有什么有点和缺点?如果真的像FP鼓吹者说的那样完美,为啥实际应用中不多见?
什么是函数式编程?
要回答这些问题,我们要先来看看函数式编程的定义。像OO(面向对象)的编程思想一样,FP(函数式)编程也只是一个programming paradigm而以。这个想法大致来说,包含两点:
- 一切都是纯函数
- 没有共享状态、可变状态、没有副作用
- 用纯函数构建一切
第一条很容易理解,函数是一等公民,你可以把函数赋予变量,也可以把函数作为参数传给其他函数或作为返回值。
对于第二条来说,我们写程序中经常用到的常量(let a = 0;)就不存在了。有些介绍FP的文章笼统的描述为FP里所有的变量都是final的,这其实是误解。FP里面没有变量的概念,全部是纯函数,取代前面那段代码的应该是:let a = () =>0;。没错,a虽然可以看作一个final的变量,但其实看作一个返回0的纯函数而以。
对于第三条,一个常见的疑问就是:没有变量还能正常写逻辑吗?答案是:完全可以。λ演算和图灵机已经被证明了是具有同样能力,任何命令式语言能做的函数式语言也都能做到。(比如Lisp、ML、Haskell)。
比如反转字符串的方法,完全可以不用临时变量而用递归:
function reverse(str:string) {
if(str.length === 0) {
return str;
}
else {
return reverse(str.substr(1, str.length)) + str.substring(0, 1);
}
}
函数式编程的优点
看到上面那段递归,可能有人就会问了:为什么我要吃饱了撑的把代码写这么奇葩?递归不是吃内存又慢么?还别说,如果能完全函数式,好处可是大大的有!
测试
如果一个方法是纯函数的,意为着这个方法的返回值依赖且只依赖于输入值。我不需要去mock一大堆全局的依赖来测试这个方法了。我只需要提供输入值,然后检查下返回值是不是预期的就行,不要太简单。
调试
在实际的项目中,你有没有被有些无法确定触发条件的bug而烦恼呢?函数式编程可没有这种烦恼,如果一个函数在某个输入值下出错,他就一定会每次都出错!更妙的是,由于一定没有读取、改变全局变量啊什么的,只要输入一样,无论是本机、测试机、还是生产机,都必然能重现出这个错误!想想以前去服务器上打log、翻日志,企图重现某个bug的日子,现在能在本地重现,是不是有点小激动!
并发及部署
假设我们有如下一段程序:
let a = funcA();
let b = funcB();
let c = funcC(a,b);
//或者更functional的写法
let c = funcC(funcA(),funcB());
//或者惰性求值
let c = funcC(funcA,funcB);
如果funcA和funcB都是比较耗时的,我能不能把这两个function改成并行跑呢?在指令式环境下,这需要仔细分析、评估funcA和funcB是否使用/修改了外部资源、有没有互相影响后才行。而如果是纯FP的话,甚至编译器就可以自动完成这两个function的拆分和并发工作,因为两个不同的function,必然是不互相影响的。
基于相同的道理,在FP的场景下,我如果修改了funcA,比如说修正了一个bug。我不需要重启整个应用,只要有办法热替换这个funcA就行了(目标:100%在线时间达成!)。
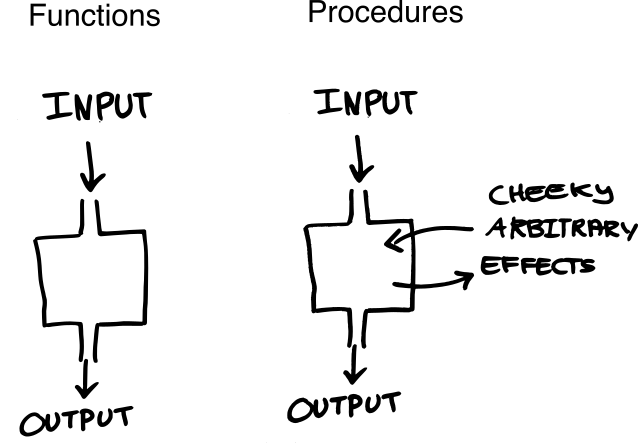
如何处理纯函数的side effect
上面一部分介绍了函数式编程的好处。那么,在一个真实的项目里,我们需要把我们的信息打印到某个地方,我们需要读取用户的输入,我们需要通过网络发送请求到其他服务。绝大部分情况下一个真实的项目的目的就是对现有资源产生修改:文件修改、数据库修改等。我们怎么可能通过纯函数(没有side effect)来构建一个必然会产生side effect的系统呢?
一个简短的回答是:能,但是他们利用函数式的规则“作弊”了,就像很多数学家一样。
当然,这里的作弊,是指他们利用规则上的漏洞,撑开了足够大的口子(事实上一个大象都能通过的口子),来实现系统。他们主要做了以下两点:
- 依赖注入DI
- 懒加载
依赖注入
让我们从一个简单的打日志函数来说起吧:
//version IP
function log(message: string): void {
const date = new Date().toISOString();
console.log(`${date}: ${message}`);
}
很显然,这个函数是不纯的。首先它依赖于系统的时间,其次他依赖于console来进行IO。我们如何把这个改成纯函数呢?答案是依赖注入:把所有的依赖变成参数注入进来。
//version FP
function log(message: string, date: Date, cnsl: Console): void {
const dt = date.toISOString();
cnsl.log(`${dt}: ${message}`);
}
乍一看这有点蠢,因为某种意义上说,我们只是把side effect抛给上一层调用方了。然而,仔细想想,这样的改动会带来前一段说过的函数式编成的各种好处。
举个例子:IP版本的log函数是很难测试的,因为你每次调用都会hit到不同的时间值。FP版本的就没有这个问题:
const date = {toISOString: () => ``};
const cnsl = {
log: (msg) => msg
};
log("hello world", date, cnsl);
在上面的例子中,我们把log转换成了纯函数,不依赖全局变量比如Date、console,只要给定相同的参数祖,一定会得到相同的结果。上面我们轻易的mock了Data和consle。那我们是不能能靠这种转换,创建一个正常的应用呢?理论上是可能的。我们可以用DI,把所有的动态依赖一层一层网上推,直到应用的启动命令为止。
app(new Date(),cnsl,aaa,bbb,ccc,...,blabla);//with 100 other parameters
有点难以接受是吧,但是,如果说启动命令参数过多是一个可以理解的缺点,另外一个缺点就是过深的参数传递。
以React为例子:React中上下层组件的数据传递是通过constructor注入props或事件回调来实现的。现在我们假设有6层的组件嵌套,第1层组件与6层组件需要处理同一份数据会怎么样?第一层不断的向子组件传递数据,然后子组件向外抛事件,这条组件链上的所有组件都必须要缓存监听这个数据。那么,如果中间有一个组件不小心处理了这个数据并且错了会怎么样?这个时候你只能一层层的往外排查所有的组件,因为整个过程是黑盒,你根本不知道到底是哪个组件搞得事,排查这么多层是不是想想都有点小激动呢?(这也是为什么会有Redux、Mobx的原因之一)
顺便一提React,最近出了个Hooks来解决类似的,组件嵌套过深时如何传播数据的问题。额,通过建立一个监听所有组件生命周期的hook注入机制(我们函数式编程是不存在全局变量的,这辈子都不会有,嘿嘿)
懒加载
让我们先来看这段绕口令:一个side effect并不是一个side effect直到这个side effect实际被调用。怎么理解呢,先看如下代码:
function lunch(): void {
//Detonate a nuclear bomb
}
一经调用,如假包换的发射一枚核弹。当然,如果我们不想引发doomsday的话,我们可以利用下first-class functions,把这个函数包装下:
function readyToLunch(): Function {
return lunch;
}
let bomb1 = readyToLunch();
//no nuclear bomb lunched!
let bomb2 = readyToLunch();
bomb1 === bomb2; //true
你看,我们还顺便验证了这个readyToLunch是个纯函数,即每次调用的返回值是同一个。事实上,我们可以用这种方式构建一个系统执行的链,把系统中的所有逻辑都通过懒加载来实现。
我写了个简单的Chain Promise的例子,项目源代码在这里。达到的效果是这样的。
let chain = ChainPromise.from(promise)
.map(x => {
//remove me to make this function pure
console.log(x, "+1");
return x + 1;
})
.map(x => {
//remove me to make this function pure
console.log(x, "+2");
return Promise.resolve(x + 2);
})
.flatMap(x => {
//remove me to make this function pure
console.log(x, "*", x);
return x * x;
})
.map(x => {
//remove me to make this function pure
console.log(x, "-5");
return x - 5;
});
chain.subscribe(console.log, console.error);
这一串操作,map或者flatmap之后,所产生的chain是个确定的值。因为每个函数都是懒加载,如果第一个promise没有被resolve或者没有人subscribe,是不会被执行的。没执行=没有side effect,problem resolved!
以下为这个chain promise的代码(也就20行不到而已):
export class ChainPromise {
static of = (v: any) => new ChainPromise(() => Promise.resolve(v));
static from = (v: Promise<any>) => new ChainPromise(() => v);
constructor(public f: (...args) => Promise<any>) {
}
map(g): ChainPromise {
return new ChainPromise(x => Promise.resolve(this.f(x)).then(v => g(v)));
}
flatMap(g): ChainPromise {
return new ChainPromise(x => Promise.resolve(this.f(x))).map(g);
}
subscribe(onSuccess?: Function, onFail?: Function): void {
Promise.resolve(this.f()).then(x => onSuccess(x)).catch(e => onFail(e));
}
}
这样的懒加载在现实世界里有应用的例子么?假设我们有几千万几亿行数据要处理,FP的纯函数就能帮上大忙了。我们可以用纯函数实现我们自己版本的map和reduce,支持并发计算。当然,在CPU上跑这个是很没效率的,因为最大并发数量被CPU核心所限制(4核、8核、16核)。我们需要把这些纯函数跑在GPU上。(1.我们希望并发越大越好 2.每个计算任务其实不复杂 3.每个计算都是纯函数)
为了在GPU上跑这些计算任务,你就需要切实的描述出这些计算任务,然而又不执行他们,是不是就是上面的chain promise了。理想情况下,我们还需要一个框架来帮我们读取所有数据,分配到GPU上,并收集汇总数据。是的,我说的就是机器学习框架TensorFlow。
比如实现两个数字相加的逻辑,在TensorFlow里面是这么写的:
node1 = tf.constant(3.0, tf.float32)
node2 = tf.constant(4.0, tf.float32)
node3 = tf.add(node1, node2)
总结
函数式编程是个好东西。虽然我们几乎不可能在一个真实的系统中完全以纯函数来实现,但这并不妨碍我们以函数式编程来实现我们系统中的某些组件,并享受它带来的各种好处。
